Block Records and Row Records
John Mount, Nina Zumel
2021-06-11
Source:vignettes/blocksrecs.Rmd
blocksrecs.RmdBlock Records and Row Records
The theory of cdata data transforms is based on the principles:
- data has coordinates
- data is naturally grouped into records.
The idea of data coordinates is related to Codd’s 2nd rule:
Each and every datum (atomic value) in a relational data base is guaranteed to be logically accessible by resorting to a combination of table name, primary key value and column name.
The coordinatized data concept is that the exact current data realization is incidental. One can perform a data change of basis to get the data into the right format (where the physical layout of records is altered to match the desired logical layout of the data).
The idea of data records (and these records possibly being different than simple rows) is a staple of computer science: harking at least back to record-oriented filesystems.
The core of the cdata package is to supply transforms between what we call “row records” (records that happen to be implemented as a single row) and block records (records that span multiple rows). These two methods are:
All the other cdata functions are helpers allowing abbreviated notation in special cases (such as unpivot_to_blocks() pivot_to_rowrecs()) and adapters (allowing these operations to be performed directly in databases and large data systems such as Apache Spark).
The current favored idiomatic interfaces to cdata are:
-
pivot_to_rowrecs(), a convenience function for moving data from multi-row block records with one value per row to single row records. -
unpivot_to_blocks(), a convenience function for moving data from single-row records to possibly multi row block records with one row per value. -
rowrecs_to_blocks_spec(), for specifying how single row records relate to general multi-row (or block) records. -
blocks_to_rowrecs_spec(), for specifying how multi-row block records relate to single-row records. -
layout_by()or the wrapr dot arrow pipe for applying a layout to re-arrange data. -
t()(transpose/adjoint) to invert or reverse layout specifications. -
wrapr::qchar_frame()a helper in specifying record control table layout specifications. -
layout_specification(), for specifying transforms from multi-row records to other multi-row records.
Let’s look at cdata with some specific data.
For our example let’s take the task of re-organizing the iris data for a faceted plot, as discussed here.
library(cdata)
#> Loading required package: wrapr
iris <- data.frame(iris)
iris$iris_id <- seq_len(nrow(iris))
head(iris, n=1)
#> Sepal.Length Sepal.Width Petal.Length Petal.Width Species iris_id
#> 1 5.1 3.5 1.4 0.2 setosa 1To transform this data into a format ready for our ggplot2 task we design (as taught here) a “transform control table” that shows how to move from our row-oriented form into a block oriented form. Which in this case looks like the following.
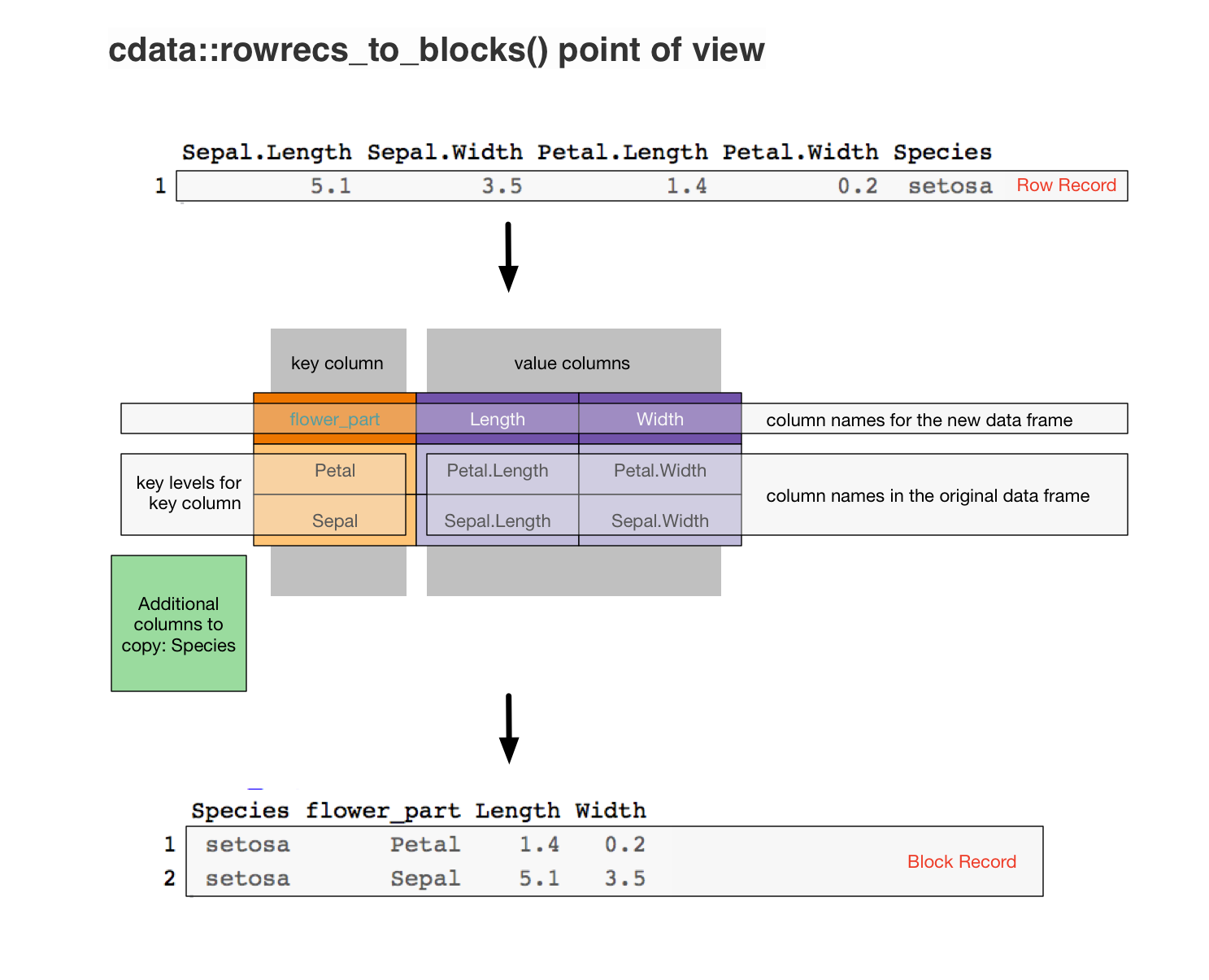
In R the transform table is specified as follows.
controlTable <- wrapr::qchar_frame(
"flower_part", "Length" , "Width" |
"Petal" , Petal.Length , Petal.Width |
"Sepal" , Sepal.Length , Sepal.Width )
layout <- rowrecs_to_blocks_spec(
controlTable,
recordKeys = c("iris_id", "Species"))
print(layout)
#> {
#> row_record <- wrapr::qchar_frame(
#> "iris_id" , "Species", "Petal.Length", "Petal.Width", "Sepal.Length", "Sepal.Width" |
#> . , . , Petal.Length , Petal.Width , Sepal.Length , Sepal.Width )
#> row_keys <- c('iris_id', 'Species')
#>
#> # becomes
#>
#> block_record <- wrapr::qchar_frame(
#> "iris_id" , "Species", "flower_part", "Length" , "Width" |
#> . , . , "Petal" , Petal.Length, Petal.Width |
#> . , . , "Sepal" , Sepal.Length, Sepal.Width )
#> block_keys <- c('iris_id', 'Species', 'flower_part')
#>
#> # args: c(checkNames = TRUE, checkKeys = FALSE, strict = FALSE, allow_rqdatatable = FALSE)
#> }And then applying it converts rows from our iris data into ready to plot 2-row blocks.
| Sepal.Length | Sepal.Width | Petal.Length | Petal.Width | Species | iris_id |
|---|---|---|---|---|---|
| 5.1 | 3.5 | 1.4 | 0.2 | setosa | 1 |
| iris_id | Species | flower_part | Length | Width |
|---|---|---|---|---|
| 1 | setosa | Petal | 1.4 | 0.2 |
| 1 | setosa | Sepal | 5.1 | 3.5 |
To perform the reverse transform we use the same transform control table, but we think of it as specifying the reverse transform (from its own block form into a row). The reverse can be specified using the t() transpose/adjoint method.
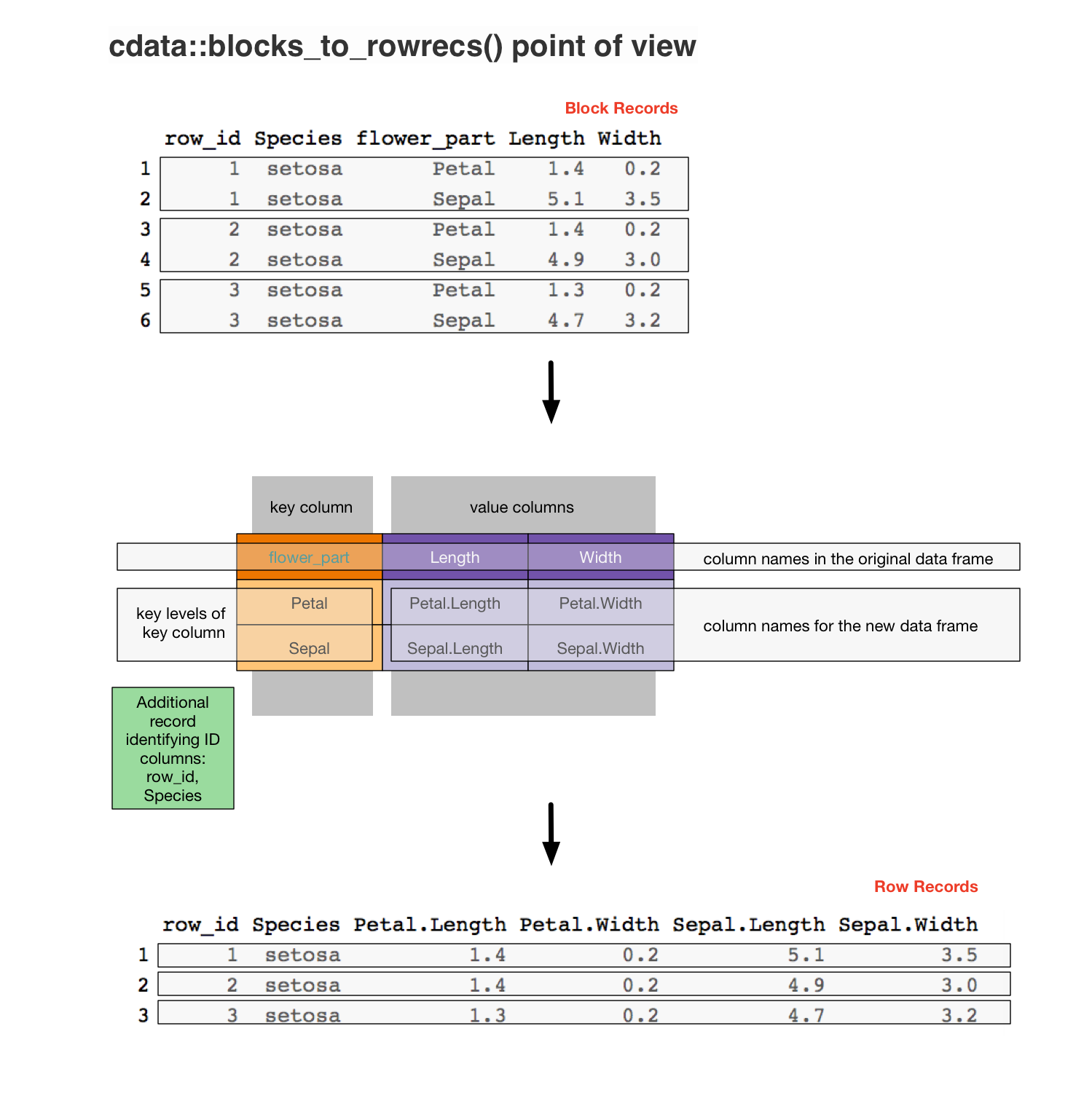
# re-do the forward transform, this time
# with more records so we can see more
iris_aug <- iris %.>%
head(., n = 3) %.>%
layout
knitr::kable(iris_aug)| iris_id | Species | flower_part | Length | Width |
|---|---|---|---|---|
| 1 | setosa | Petal | 1.4 | 0.2 |
| 1 | setosa | Sepal | 5.1 | 3.5 |
| 2 | setosa | Petal | 1.4 | 0.2 |
| 2 | setosa | Sepal | 4.9 | 3.0 |
| 3 | setosa | Petal | 1.3 | 0.2 |
| 3 | setosa | Sepal | 4.7 | 3.2 |
inv_layout <- t(layout)
print(inv_layout)
#> {
#> block_record <- wrapr::qchar_frame(
#> "iris_id" , "Species", "flower_part", "Length" , "Width" |
#> . , . , "Petal" , Petal.Length, Petal.Width |
#> . , . , "Sepal" , Sepal.Length, Sepal.Width )
#> block_keys <- c('iris_id', 'Species', 'flower_part')
#>
#> # becomes
#>
#> row_record <- wrapr::qchar_frame(
#> "iris_id" , "Species", "Petal.Length", "Petal.Width", "Sepal.Length", "Sepal.Width" |
#> . , . , Petal.Length , Petal.Width , Sepal.Length , Sepal.Width )
#> row_keys <- c('iris_id', 'Species')
#>
#> # args: c(checkNames = TRUE, checkKeys = FALSE, strict = FALSE, allow_rqdatatable = FALSE)
#> }
# demonstrate the reverse transform
iris_back <- iris_aug %.>%
inv_layout
knitr::kable(iris_back)| iris_id | Species | Petal.Length | Petal.Width | Sepal.Length | Sepal.Width |
|---|---|---|---|---|---|
| 1 | setosa | 1.4 | 0.2 | 5.1 | 3.5 |
| 2 | setosa | 1.4 | 0.2 | 4.9 | 3.0 |
| 3 | setosa | 1.3 | 0.2 | 4.7 | 3.2 |
cdata considers the row-record a universal intermediate form, and this has the advantage of being able to represent a different type per value (as each value per-record is in a different column)
This differs from reshape2 where the melt() to “molten” (or thin RDF-triple-like) is used as the universal intermediate form that one then dcast()s into desired arrangements.
As we have said, a tutorial on how to design a controlTable can be found here and here.
Some additional (older) tutorials on cdata data transforms can are given below:
Appendix
The cdata operators can be related to Codd’s relational operators as follows:
-
rowrecs_to_blocks()is a variation of a relational-join of the data with the control table. This is why you get one row per pair of original data rows and control table rows. -
blocks_to_rowrecs()is essentially an aggregation or relational-projection (actually even a coalesce) over a widened table. This is why this operation decreases the number of rows.