Who's the Best Batter? Estimating Probabilities from Unevenly Collected Data
In this article, we look at the problem of estimating and comparing probabilities about a population of subjects from unevenly collected observations. Some examples might include:
- The perceived quality of a movie (how often is a movie positively reviewed) when some movies have far more reviews than others.
- The effectiveness of various ad campaigns, when some compaigns have had more exposure than others.
- The efficacy of a certain medical procedure by hospital, when some hospitals have had more cases than others.
For our specific task, we'll try to estimate the "innate" batting ability (the probability of making a hit when at bat)[1] of major league baseball players in 2023[2]. For the sake of this article, we will take this single season of data as everything that we know about these players and their batting statistics.
First, let's take a quick look at the data.
battingf = pd.read_csv(datadir + 'battingstats.tsv', sep = "\t")
battingf| playerID | atbat | hits | batting_avg | |
|---|---|---|---|---|
| 0 | abramcj01 | 563 | 138 | 0.245115 |
| 1 | abreujo02 | 540 | 128 | 0.237037 |
| 2 | abreuwi02 | 76 | 24 | 0.315789 |
| 3 | acunaro01 | 643 | 217 | 0.337481 |
| 4 | adamewi01 | 553 | 120 | 0.216998 |
| ... | ... | ... | ... | ... |
| 651 | yoshima02 | 537 | 155 | 0.288641 |
| 652 | youngja02 | 43 | 8 | 0.186047 |
| 653 | youngja03 | 107 | 27 | 0.252336 |
| 654 | zavalse01 | 175 | 30 | 0.171429 |
| 655 | zuninmi01 | 124 | 22 | 0.177419 |
656 rows × 4 columns
We can calculate some summary statistics, too.
Click to see code
nplayers = battingf.shape[0]
print(f'Population of {nplayers} players.')
mean_ba = battingf['batting_avg'].mean()
std_ba = battingf['batting_avg'].std()
print(f'Mean batting average: {mean_ba:.2f}, standard deviation {std_ba:.2f}')
mean_atbat = battingf['atbat'].mean()
std_atbat = battingf['atbat'].std()
print(f'Mean at bats: {mean_atbat:.2f}, standard deviation {std_atbat:.2f}') Population of 656 players.
Mean batting average: 0.23, standard deviation 0.07
Mean at bats: 250.64, standard deviation 192.45
Given this information, how do we estimate players' batting ability?
You may be tempted to simply use a player's observed batting average as an estimate of their batting skill. One issue with this is that not all players get the same number of at-bats. Let's look at the batting averages for all the players, sorted by their number of times at bat. The horizontal line on the graph represents the mean batting average of the population.
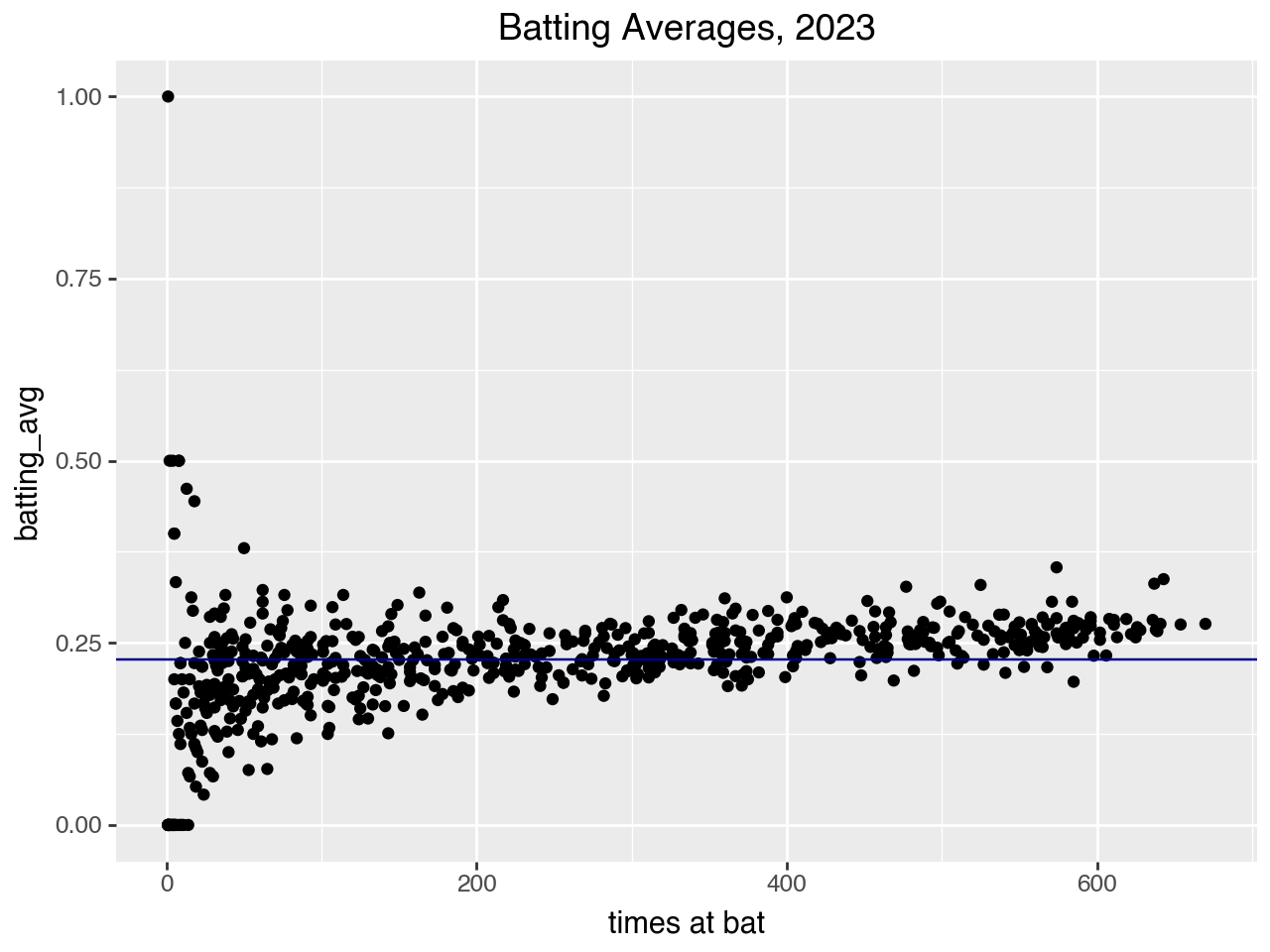
Batting averages versus times at bat. Dark blue horizontal line represents population mean batting average.
As you can see, the number of at-bats for players in 2023 varied widely; some players were up hundreds of times, and some fewer than ten times. For players with a lot of at-bats, their observed batting average is probabably a good estimate of their innate batting ability. But for players with fewer at-bats, their observed batting average is more likely to be an over or under estimate of their ability.
Finding the Top 10 Batters
We can make this point dramatically by using our naive batting ability estimates to answer the question, Who are the top 10 batters?
naive_top10 = battingf.nlargest(10, 'batting_avg')
naive_top10| playerID | atbat | hits | batting_avg | |
|---|---|---|---|---|
| 140 | culbech01 | 1 | 1 | 1.000000 |
| 124 | colliza01 | 4 | 2 | 0.500000 |
| 325 | lopezal03 | 2 | 1 | 0.500000 |
| 450 | perezmi03 | 8 | 4 | 0.500000 |
| 593 | tuckeco01 | 8 | 4 | 0.500000 |
| 626 | wallfo01 | 13 | 6 | 0.461538 |
| 583 | toroab01 | 18 | 8 | 0.444444 |
| 165 | downsje01 | 5 | 2 | 0.400000 |
| 229 | graytr01 | 5 | 2 | 0.400000 |
| 121 | clemeer01 | 50 | 19 | 0.380000 |
Do you trust this ranking? Probably not---notice that most of the players in the top ten using this naive measure have actually been at bat very few times, and their batting averages are unrealistically high. Remember: the average batting average in the league for this season is 0.23, and the standard deviation is small. Batting averages of 1.0 or even 0.5 are highly improbable estimates of actual player ability.
This is analogous to sorting the rankings of a product on an online shopping site[3]. Which assessment would you consider more reliable:
- one with a five-star average rating calculated from only one or two ratings,
- or one with a 4.5 star rating calculated from 200 ratings?
Personally, I would be more likely to trust the assesment of the second product.
Given that our observations of the players are so uneven, is there a better way estimate how good a batter each player really is?
We would like a method that handles players with very few observations in a reasonable way. If a player has been at bat only once, their observed batting average is either 1 or 0: either they look perfect, or they look terrible. Since they are most likely neither, we'd like to assume a reasonable estimate of their batting ability, one we can use while we are waiting for more data. And of course, we want a method where the estimate improves as more data becomes available.
Estimating Batting Ability with Probabilistic Modeling
One approach that robustly handles players with few at-bats is probabilistic modeling. In this article, we will implement a probabilistic model for the batting ability problem using Stan. We won't explain the Stan code in depth, but we will try to explain what the model is doing.
The idea behind this model is that a player's empirical batting performance is merely an observable approximation of the player's unobservable "innate batting ability," which we'll define as the probability that a batter will make a hit when he or she is at bat. This is illustrated in the figure below.
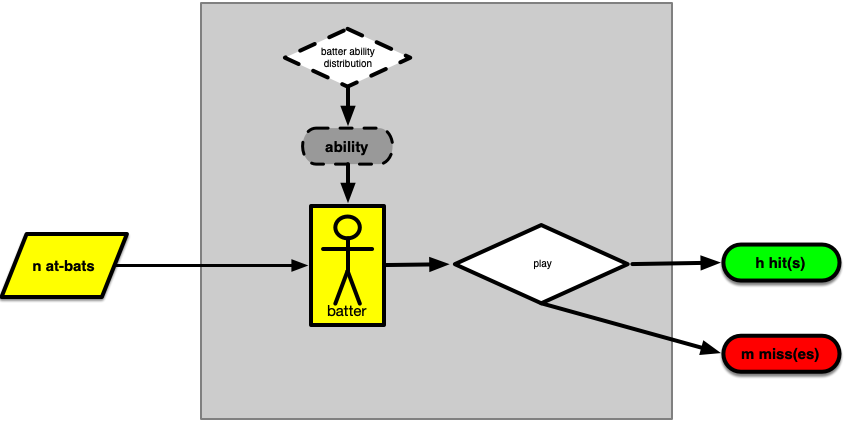
Working model of the hit generation process. An individual batter has a given (unobservable) batting ability, drawn from the distribution of batting abilities for the population. For the player's n at-bats, we observe the number of hits and misses during play.
In order to estimate player batting ability, which we cannot directly observe, we will define a probabilistic process to "explain" the observable batting performance in terms of the unobservable player ability.
Specifically, we'll model each player as a coin, where a hit is "heads", and the number of at-bats is the number of flips. We'll call the (unknown) probability of coming up heads (getting a hit) gamma. Then we can model each player as a binomial:
hits_i ~ binomial(atbat_i, gamma_i)
In other words, gamma is the player's innate batting ability.
We'll further assume that the player gammas are distributed around some (also unknown) "global player batting ability." The idea here is that all the players come from the same population, so their batting performances are somewhat similar. This implies that player batting abilities tend to cluster around some average batting ability, and very high (or low) abilities are unlikely.
This is only an assumption, but we consider it plausible because of real-life observations like "batting averages for professional players tend to be around 0.25ish, and super high batting averages are unlikely"---an observation we can back up with the data.
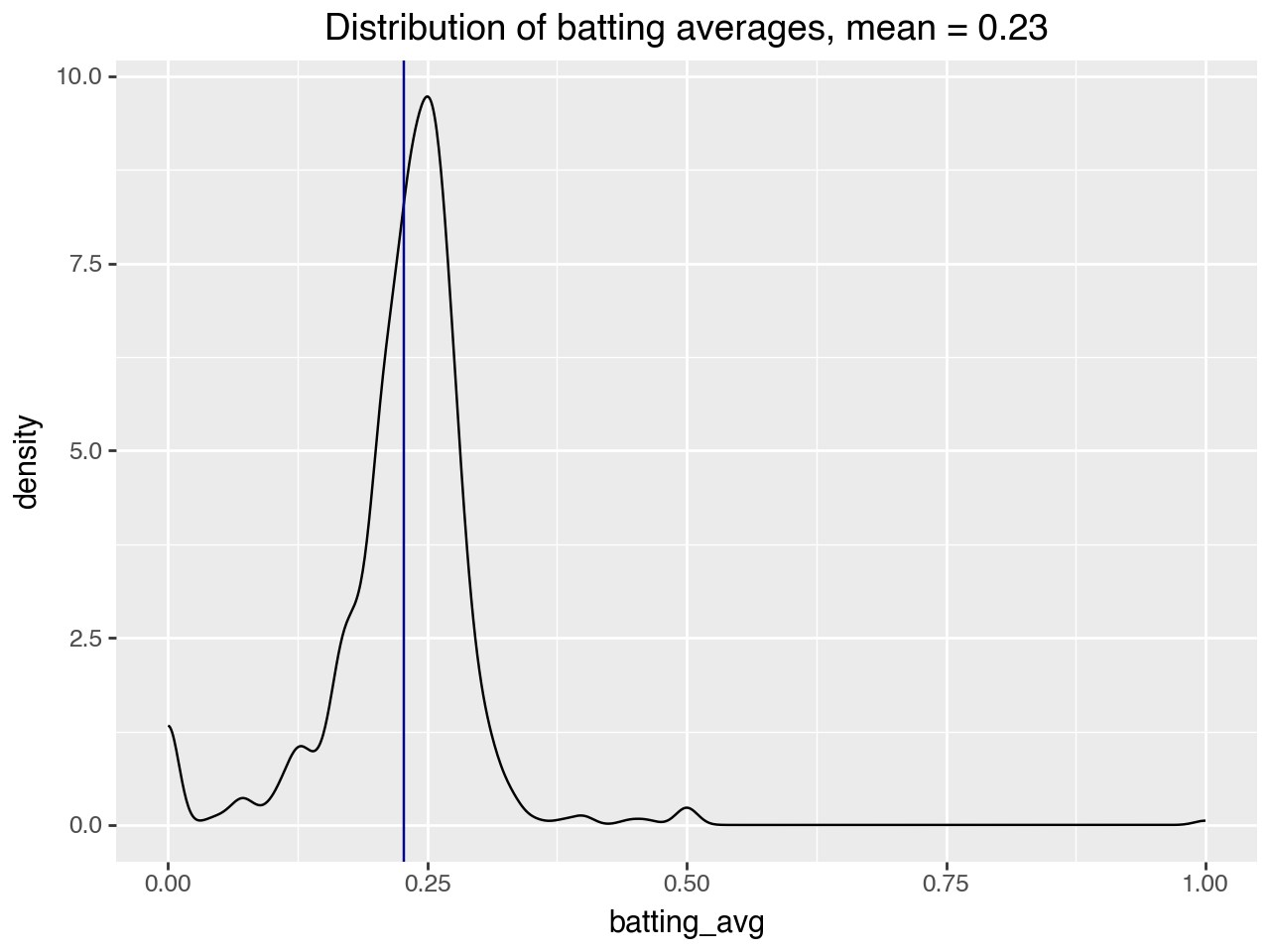
Distribution of observed batting averages for the 2023 MLB season.
An advantage of probabilistic modeling is that it allows us to incorporate these types of assumptions or domain knowledge into our analysis in a principled way. With more common frequentist analyses, like the above naive approach, we don't have a way to express notions like "player abilities are in a tight, non-uniform distribution," without resorting to ad-hoc rules such as "only consider batters who have more than 100 at-bats."
To continue: we want to model the "global player batting ability" as a distribution from which individual player gammas are drawn. Since the players are binomial, we'll assume that the gammas are distributed as a beta distribution.
gamma ~ beta(a, b)
In Bayesian parlance, the distribution beta(a, b) represents the priors on gamma (player batting ability). For a player with only a few at-bats, there is little information on their individual ability, so the model will estimate that their batting ability is near some average batting ability. For players with many at-bats, the model will have enough information to pull the estimate away from the grand mean.
Intuitively, the parameters a and b represent a "pseudo-hits" for a+b "pseudo-atbats". The larger a+b is, the more observations will be required to pull a player's estimated ability away from the grand mean (a/(a+b)). In other words, this formulation smooths all the estimated batting averages towards some (estimated) grand mean. The quantity a+b specifies the strength of the smoothing.
We can control how much we smooth to the mean, and what the mean is, by explicitly picking a and b. In this model, however, we will use Stan to estimate a and b from the data.
Below is the code for the Stan model. Don't worry if you can't read it; the explanation above and the comments in the code should be sufficient.
stan_model_src = """
data { // this block describes the training data
int<lower=1> n_players; // number of players observed
array[n_players] int<lower=0> hits; // number of hits - needs to be integer type because of binomial call
array[n_players] int<lower=0> atbat; // number of at-bats - needs to be integer type because of binomial call
}
parameters { // this block declares the parameters to be estimated
vector<lower=0, upper=1>[n_players] gamma; // unobserved "true" batting abilities
real<lower=0> a; // pseudo-hits
real<lower=0> b; // pseudo-misses
}
model { // this block describes the relations between parameters and data
gamma ~ beta(a, b); // distribution of unobservable batting ability
hits ~ binomial(atbat, gamma); // relation of hits to per-player ability
}
"""Unlike most modeling systems, Stan does not return point estimates of the parameters it is trying to fit. It instead uses Monte Carlo sampling to jointly generate sets of parameters (called samples) that are consistent with the training data. Each of these samples (4000 of them, in this case) represents a "possible world" that could generate the observed data. We can use these possible worlds to not only calculate point estimates of the parameters we want, but also uncertainty ranges around those estimates.
Behind the scenes, we have fit the model, and saved Stan's generated samples into a data frame named fit_Stan. For all the details, see the source code linked at the top of this article.
fit_Stan.shape(4000, 668)
Estimate of the Priors
Let's look at Stan's estimates for a and b. Do we get reasonable distributions of pseudo-observations and global batting ability?
As a diagnostic on the model, we would like to see that the distributions of both a and b are unimodal (which they are, but for brevity the plots are omitted). We'd also like to see that the mean of the beta distribution is near the observed mean batting average in every sample.
Click to see code
## check the a and b estimates.
abframe = fit_Stan[['a', 'b']].copy()
abframe['pseudo_obsv'] = abframe['a'] + abframe['b']
abframe['global_ba'] = abframe['a']/abframe['pseudo_obsv']
abframe['variance'] = abframe['a']*abframe['b']/( abframe['pseudo_obsv']**2 * (abframe['pseudo_obsv'] + 1) )
print(f"""
Mean pseudo observation estimate: {abframe['pseudo_obsv'].mean():.3f};
Mean global batting ability estimate: {abframe['global_ba'].mean():.3f}, compared to observed mean batting average {mean_ba:.3f}
""")
Mean pseudo observation estimate: 434.612;
Mean global batting ability estimate: 0.244, compared to observed mean batting average 0.227
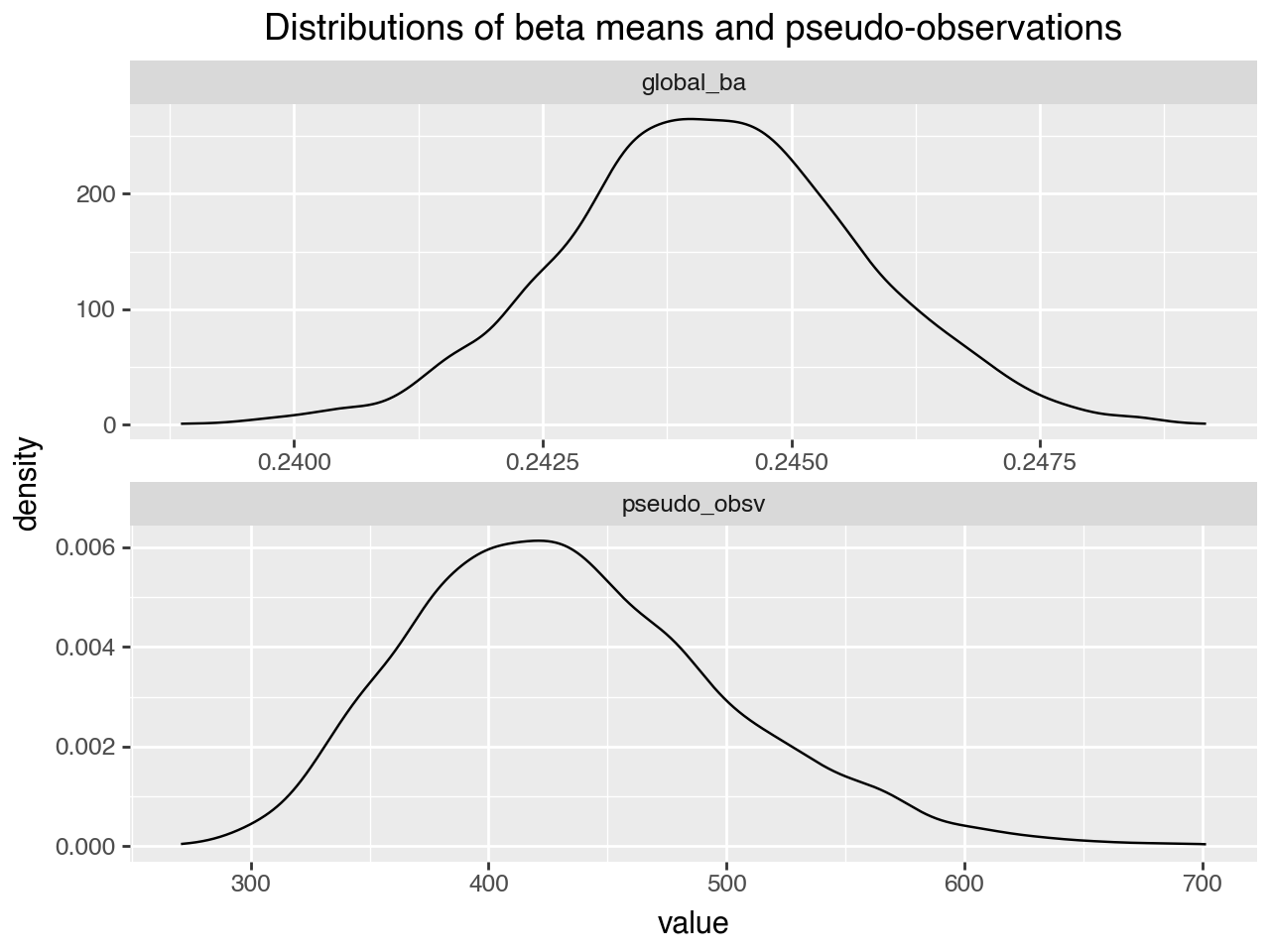
The mean of beta is generally between 0.24 and 0.25, which is not far from the observed mean batting average of 0.23. The large number of pseudo-observations corresponds to beta distributions with fairly low variance, which is again consistent with our empirical observation. It also means that there will be a lot of smoothing on the estimates.
As a sidenote, it is often common practice to add tight priors to a and b---that is, to force a+b to be small. This is both to keep the priors "uninformative," as in frequentist formulations, and to force the probability estimates to be close to the empirical observations. As we will see later in this article, allowing Stan to pick a and b such that a+b is large, reduced the variance on ability estimates, but in a way that is consistent with the real-world batting performances. Less smoothing on the estimates would have led to too much variance in batting performance.
Estimating Batting Ability
Now let's get all the samples of player gammas.
batting_estimates = fit_Stan.filter(like='gamma').copy()
batting_estimates.columns = battingf['playerID']
batting_estimates| playerID | abramcj01 | abreujo02 | abreuwi02 | ... | youngja03 | zavalse01 | zuninmi01 |
|---|---|---|---|---|---|---|---|
| 0 | 0.255413 | 0.248422 | 0.258750 | ... | 0.253605 | 0.227349 | 0.222809 |
| 1 | 0.244398 | 0.217937 | 0.251756 | ... | 0.283892 | 0.217628 | 0.237123 |
| 2 | 0.243953 | 0.258032 | 0.263147 | ... | 0.208346 | 0.220289 | 0.219931 |
| 3 | 0.249291 | 0.242690 | 0.261040 | ... | 0.265126 | 0.221886 | 0.227214 |
| 4 | 0.237667 | 0.251283 | 0.240370 | ... | 0.233977 | 0.219615 | 0.237419 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 3995 | 0.259563 | 0.245729 | 0.300755 | ... | 0.223936 | 0.206689 | 0.249676 |
| 3996 | 0.245689 | 0.236702 | 0.238916 | ... | 0.249938 | 0.214311 | 0.234321 |
| 3997 | 0.224689 | 0.227445 | 0.234514 | ... | 0.274076 | 0.252756 | 0.234653 |
| 3998 | 0.228148 | 0.233065 | 0.252618 | ... | 0.233102 | 0.257751 | 0.235676 |
| 3999 | 0.263306 | 0.248453 | 0.251055 | ... | 0.256680 | 0.194360 | 0.225084 |
4000 rows × 656 columns
Each row represents a combination of player batting abilities that is consistent with the training data.
For every player, we can use the above set of Stan estimates to get a point estimate of their gamma (we'll use the mean; you can also use the median), and an uncertainty interval that covers 95% of the Stan estimates.
Click to see code
nplayers = battingf.shape[0]
means = [np.mean(batting_estimates.iloc[:, i]) for i in range(nplayers)]
# calculate the 95% uncertainty interval
intervals = [np.percentile(batting_estimates.iloc[:, i], [2.5, 97.5]) for i in range(nplayers)]
interval_bottom = [interv[0] for interv in intervals]
interval_top = [interv[1] for interv in intervals]
battingf['gamma'] = means
battingf['g_min'] = interval_bottom
battingf['g_max'] = interval_top
battingf
| playerID | atbat | hits | batting_avg | gamma | g_min | g_max | |
|---|---|---|---|---|---|---|---|
| 0 | abramcj01 | 563 | 138 | 0.245115 | 0.244644 | 0.217479 | 0.271896 |
| 1 | abreujo02 | 540 | 128 | 0.237037 | 0.240080 | 0.212640 | 0.266951 |
| 2 | abreuwi02 | 76 | 24 | 0.315789 | 0.254437 | 0.215732 | 0.295471 |
| 3 | acunaro01 | 643 | 217 | 0.337481 | 0.300198 | 0.271661 | 0.330569 |
| 4 | adamewi01 | 553 | 120 | 0.216998 | 0.228769 | 0.202451 | 0.256487 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 651 | yoshima02 | 537 | 155 | 0.288641 | 0.268467 | 0.240529 | 0.297654 |
| 652 | youngja02 | 43 | 8 | 0.186047 | 0.238932 | 0.201439 | 0.278378 |
| 653 | youngja03 | 107 | 27 | 0.252336 | 0.245744 | 0.209507 | 0.283893 |
| 654 | zavalse01 | 175 | 30 | 0.171429 | 0.223203 | 0.190155 | 0.258194 |
| 655 | zuninmi01 | 124 | 22 | 0.177419 | 0.229210 | 0.194561 | 0.265152 |
656 rows × 7 columns
Point estimates of batting abilities, along with upper and lower bounds on 95% uncertainty intervals
The Top 10 Batters, According to Stan
Here is the roster of top 10 batters, according to the Stan point estimates. Notice that all the players in this roster have been at bat hundreds of times, so we can consider this top 10 to be more trustworthy.
| playerID | atbat | hits | batting_avg | gamma | g_min | g_max | |
|---|---|---|---|---|---|---|---|
| 34 | arraelu01 | 574 | 203 | 0.353659 | 0.306837 | 0.278873 | 0.336221 |
| 3 | acunaro01 | 643 | 217 | 0.337481 | 0.300198 | 0.271661 | 0.330569 |
| 200 | freemfr01 | 637 | 211 | 0.331240 | 0.296087 | 0.268344 | 0.324402 |
| 158 | diazya01 | 525 | 173 | 0.329524 | 0.291116 | 0.262371 | 0.321038 |
| 520 | seageco01 | 477 | 156 | 0.327044 | 0.287488 | 0.258570 | 0.318180 |
| 61 | bettsmo01 | 584 | 179 | 0.306507 | 0.280108 | 0.253704 | 0.307470 |
| 62 | bichebo01 | 571 | 175 | 0.306480 | 0.279565 | 0.252326 | 0.307508 |
| 53 | bellico01 | 499 | 153 | 0.306613 | 0.277572 | 0.249387 | 0.306813 |
| 469 | ramirha02 | 400 | 125 | 0.312500 | 0.277267 | 0.247371 | 0.310371 |
| 410 | naylojo01 | 452 | 139 | 0.307522 | 0.276918 | 0.247745 | 0.308113 |
The top 10 batters, as given by the Stan point estimates of batter ability
Let's plot the top 10 players' gammas, along with their observed batting average and the estimated global mean batting ability.
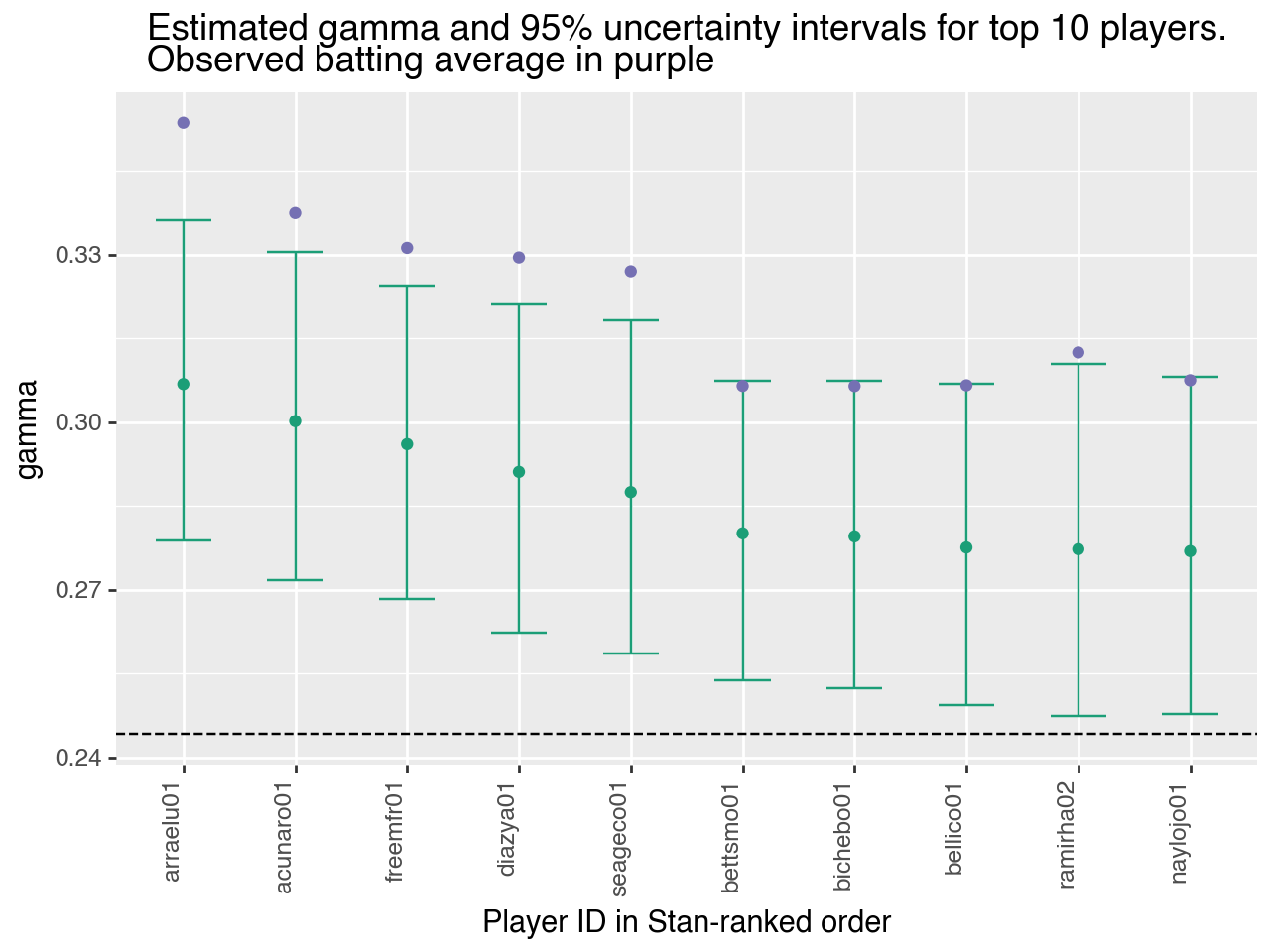
Gamma estimates for the top 10 batters. Gamma and 95% uncertainty intervals in green; observed batting averages in purple. The horizontal dashed line is the estimated mean player batting ability.
You might wonder why the observed batting averages are consistently so much higher than the estimated batting abilities. This is because the model is smoothing all the estimates towards the priors. Hence, performance estimates for high performing batters will be biased down, and performance estimates for low performing batters will be biased up. This is not a property unique to Stan; it is a property of the smoothing process.
It is also worth pointing out, however, that the uncertainty intervals are away from the estimated global mean (horizontal dashed line), indicating that the model identifies these players as having above average batting ability. Furthermore, the ranking order of the players according to their gamma estimates is generally consistent with the ranking of their empirical batting averages.
What about the players with very few at-bats? As desired, their gammas are near the estimated global mean of 0.24.
| playerID | atbat | hits | batting_avg | gamma | g_min | g_max | |
|---|---|---|---|---|---|---|---|
| 46 | barretr01 | 2 | 0 | 0.0 | 0.243261 | 0.204423 | 0.284172 |
| 111 | castidi02 | 1 | 0 | 0.0 | 0.243484 | 0.202068 | 0.287601 |
| 124 | colliza01 | 4 | 2 | 0.5 | 0.246683 | 0.206278 | 0.288201 |
| 140 | culbech01 | 1 | 1 | 1.0 | 0.245780 | 0.207254 | 0.286393 |
| 165 | downsje01 | 5 | 2 | 0.4 | 0.246108 | 0.206405 | 0.287695 |
| 205 | fulmemi01 | 1 | 0 | 0.0 | 0.243642 | 0.205138 | 0.284218 |
| 229 | graytr01 | 5 | 2 | 0.4 | 0.245800 | 0.205371 | 0.288453 |
| 242 | hamilbi02 | 2 | 0 | 0.0 | 0.243317 | 0.205493 | 0.283204 |
| 243 | hamilca01 | 5 | 0 | 0.0 | 0.241302 | 0.203104 | 0.282519 |
| 290 | kaiseco01 | 4 | 0 | 0.0 | 0.241975 | 0.202445 | 0.282454 |
| 325 | lopezal03 | 2 | 1 | 0.5 | 0.245427 | 0.205673 | 0.287053 |
| 362 | mccoyma01 | 1 | 0 | 0.0 | 0.243813 | 0.205295 | 0.285935 |
| 386 | millesh01 | 1 | 0 | 0.0 | 0.243820 | 0.204505 | 0.284791 |
| 388 | mitchca01 | 4 | 0 | 0.0 | 0.241544 | 0.201192 | 0.284165 |
| 424 | okeych01 | 2 | 0 | 0.0 | 0.242944 | 0.202513 | 0.285449 |
| 482 | reynoma03 | 5 | 1 | 0.2 | 0.243430 | 0.204012 | 0.285005 |
| 514 | sborzjo01 | 1 | 0 | 0.0 | 0.243737 | 0.203860 | 0.285506 |
| 521 | seaglch01 | 1 | 0 | 0.0 | 0.243371 | 0.203613 | 0.285376 |
| 527 | shewmbr01 | 4 | 0 | 0.0 | 0.241642 | 0.200795 | 0.284840 |
| 529 | sianimi01 | 5 | 0 | 0.0 | 0.241498 | 0.201679 | 0.283838 |
| 614 | vilorme01 | 3 | 0 | 0.0 | 0.242547 | 0.202917 | 0.283509 |
| 622 | wainwad01 | 2 | 0 | 0.0 | 0.242655 | 0.203335 | 0.284259 |
Observed batting averages and estimated batting ability for players with five or fewer at-bats.
Who's the best player? Another way to choose
If our goal is in fact to choose the player(s) with the highest batting ability, there is another way to do it, using the "possible worlds" sampled by Stan. For each one of the 4000 possible worlds, we identify the highest ability player. The "true" best player is most likely the one who is best in the most possible worlds.
Below, we find the best player in every Stan sample, and pick our top 10 accordingly. We could of course pick the top 10 in each possible world, and draw our "most likely top 10" from the resulting sets, but picking the single best is easier to code, and gets the point across.
Click to see code
# get the best performance in each sample world
best_perf = batting_estimates.max(axis=1)
# mark which player was the best in each world. ties ok
is_best = batting_estimates.eq(best_perf, axis=0).astype(int)
# compute the series and convert it to a data frame
mean_best = is_best.mean().reset_index()
mean_best.columns = ['playerID', 'frac_as_best']
# join it into battingf
battingf = battingf.merge(mean_best, on='playerID')
# top 10 by fraction best
top10_by_frac = battingf.nlargest(10, 'frac_as_best')
top10_by_frac[['playerID', 'frac_as_best', 'batting_avg', 'gamma']]| playerID | frac_as_best | batting_avg | gamma | |
|---|---|---|---|---|
| 34 | arraelu01 | 0.33250 | 0.353659 | 0.306837 |
| 3 | acunaro01 | 0.18100 | 0.337481 | 0.300198 |
| 200 | freemfr01 | 0.11000 | 0.331240 | 0.296087 |
| 158 | diazya01 | 0.06425 | 0.329524 | 0.291116 |
| 520 | seageco01 | 0.04150 | 0.327044 | 0.287488 |
| 469 | ramirha02 | 0.01650 | 0.312500 | 0.277267 |
| 62 | bichebo01 | 0.01250 | 0.306480 | 0.279565 |
| 410 | naylojo01 | 0.01075 | 0.307522 | 0.276918 |
| 61 | bettsmo01 | 0.01050 | 0.306507 | 0.280108 |
| 53 | bellico01 | 0.00975 | 0.306613 | 0.277572 |
Too 10 batters, calculated by how often each player ranked best in a Stan sample.
This is substantially the same set of players as were selected by looking just at the point estimates. That's good! It gives us confidence that these are indeed the players with the highest batting ability.
Let's mark the players who show up in the top 10, by either criterion. We'll also check for differences in the two top 10 sets.
Click to see code
top10_by_frac = set(battingf.nlargest(10, 'frac_as_best')['playerID'])
top10_by_gamma = set(battingf.nlargest(10, 'gamma')['playerID'])
# take a look at the differences in the sets
print(f'Picked by point estimate but not by fraction best: { top10_by_gamma.difference(top10_by_frac) }')
print(f'Picked by fraction best but not by point estimate: { top10_by_frac.difference(top10_by_gamma) }')
in_top10_set = top10_by_gamma.union(top10_by_frac)
in_top10 = battingf['playerID'].isin(in_top10_set)
battingf['in_top10'] = in_top10.astype(str)
battingf.loc[battingf['in_top10']=='True', ['playerID', 'atbat', 'hits', 'batting_avg', 'gamma', 'frac_as_best']] Picked by point estimate but not by fraction best: set()
Picked by fraction best but not by point estimate: set()
| playerID | atbat | hits | batting_avg | gamma | frac_as_best | |
|---|---|---|---|---|---|---|
| 3 | acunaro01 | 643 | 217 | 0.337481 | 0.300198 | 0.18100 |
| 34 | arraelu01 | 574 | 203 | 0.353659 | 0.306837 | 0.33250 |
| 53 | bellico01 | 499 | 153 | 0.306613 | 0.277572 | 0.00975 |
| 61 | bettsmo01 | 584 | 179 | 0.306507 | 0.280108 | 0.01050 |
| 62 | bichebo01 | 571 | 175 | 0.306480 | 0.279565 | 0.01250 |
| 158 | diazya01 | 525 | 173 | 0.329524 | 0.291116 | 0.06425 |
| 200 | freemfr01 | 637 | 211 | 0.331240 | 0.296087 | 0.11000 |
| 410 | naylojo01 | 452 | 139 | 0.307522 | 0.276918 | 0.01075 |
| 469 | ramirha02 | 400 | 125 | 0.312500 | 0.277267 | 0.01650 |
| 520 | seageco01 | 477 | 156 | 0.327044 | 0.287488 | 0.04150 |
Players marked as belonging to top 10 by either ranking criterion.
Comparing the Naive Ranking to Stan's Ranking
Now let's plot all the players, sorted by observed batting average (lowest to highest). We'll plot the estimated player ability (gamma), along with the 95% uncertainty intervals around the estimates (in light gray). The points are also color coded by whether or not the player made at least one of the top 10 lists (in green) or not (in purple). The dashed line is the estimated mean player ability.
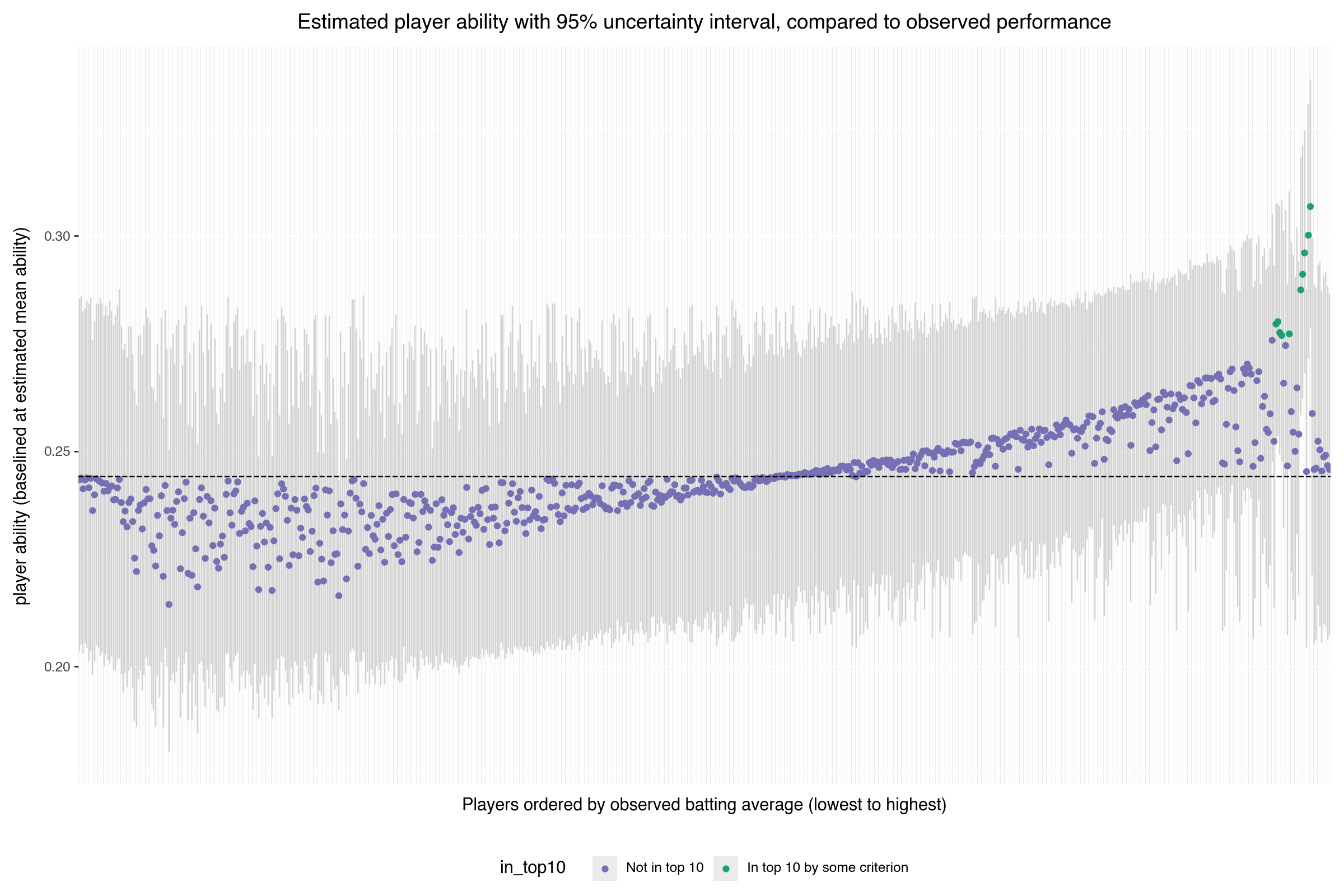
Estimated player abilities, with players sorted by observed batting average (lowest to highest). Green points indicate top 10 batters. 95% uncertainty intervals on ability estimates shown in gray. Dashed line represents estimated mean player ability. Right click on image to get full size version.
There are a few things to note in this graph. First, the ranking of ability estimates roughly correlate with the ranking of observed batting averages, as desired. There is a cluster of purple players to the right of the green players who have relatively low (actually, average) estimated batting ability, but high observed batting average. These are the players who weren't at bat very often, but who were successful when they were. The model did not have enough data on these players to move the ability estimates away from the prior. Similarly, there are players at the far left of the graph who cluster around the mean, even though their observed batting averages are zero, or nearly so. These are also players with only a few at bats, so their estimated abilities still smooth strongly into the prior.
So if the goal of estimating player ability is to identify the best players, then this model has been able to do so. It automatically discounts spurious empirical estimates that are likely inaccurate due to insufficient data, without the analyst having to specify what "insufficient data" is in an ad-hoc way. It also provides reasonable assumptions about the abilities of low information (low at-bat) players---assumptions that are based on the population data.
Comparing the Model to Reality
Here are the three players who were most often ranked best in a Stan sample.
| playerID | frac_as_best | batting_avg | gamma | career batting average | |
|---|---|---|---|---|---|
| 34 | arraelu01 | 0.3325 | 0.353659 | 0.306837 | 0.317 |
| 3 | acunaro01 | 0.1810 | 0.337481 | 0.300198 | 0.288 |
| 200 | freemfr01 | 0.1100 | 0.331240 | 0.296087 | 0.299 |
Top Three Players, probability of being best player, observed 2023 batting average, estimated batting ability, and career batting average as of May 2026.
The top player, arraelu01, is best-ranked by both "probability of being best" and point estimate criteria. He is Venezuelan-born infielder, Luis Arráez. Here's what his Wikipedia page has to say about him:
Known for his ability to put the ball in play and not striking out, Arráez is considered one of the best contact hitters of his generation. From 2022 to 2024, Arráez became the first player in MLB history to win three consecutive batting titles with three different teams.... He was also the second player in the modern era to win a batting title in each league and the first to do so in consecutive years.
Note that his career MLB batting average[4] (calculated from 2019 through May 17, 2026) is 0.317. This is pretty close to our estimated gamma of 0.307. In fact, our estimate is a better prediction of Arráez's career performance (so far) than the simple observation of his 2023 season batting average is---even though we estimated his ability using only this single season!
The next two players (as ranked by probability of being best) are Ronald Acuña, Jr. and Freddie Freeman. Note that for all these players, both Stan's batting ability estimate and player career batting average are below their observed 2023 season batting averages---showing that smoothing performance estimates to the population mean was a reasonable modeling choice. Note also that the career batting averages for these top three players also fell within the 95% uncertainty intervals of ability, as estimated by Stan.
Matching Summaries
Let's further compare Stan's batting ability estimates with observations from the data.
Click to see code
mean_ability = battingf['gamma'].mean()
std_ability = battingf['gamma'].std()
print(f'Mean observed batting average: {mean_ba:.3f}, standard deviation {std_ba:.3f}.')
print(f'Mean estimated batting ability: {mean_ability:.3f}, standard deviation {std_ability:.3f}.')Mean observed batting average: 0.227, standard deviation 0.075.
Mean estimated batting ability: 0.244, standard deviation 0.012.
As we saw previously, Stan's estimated mean batter ability is close to what was observed in the data, but the standard deviation of the ability estimates is much lower!
This is not surprising: we also know that the number of player at-bats varied widely, and players with few at-bats will have observed batting averages that will tend to over- or under- estimate their actual abilities. This is why observed batting average standard deviation is so much higher than estimated batting ability standard deviation.
In order to properly compare Stan's ability estimates to actual observations, we have to simulate the season in each Stan sample. That is, in each possible world, we give each player the same number of at-bats as they had in 2023, and generate a plausible observed batting average, given that number of at-bats. This is shown below.
Click to see code
def draw_synthetic_hitrate (atbat, bavec):
return rng.binomial(atbat, bavec)/atbat
synthetic_hitrate_frame = pd.DataFrame({
col: draw_synthetic_hitrate(battingf['atbat'][i], batting_estimates[col])
for i, col in enumerate(batting_estimates.columns)
})
synthetic_hitrate_frame| abramcj01 | abreujo02 | abreuwi02 | ... | youngja03 | zavalse01 | zuninmi01 | |
|---|---|---|---|---|---|---|---|
| 0 | 0.243339 | 0.246296 | 0.381579 | ... | 0.177570 | 0.245714 | 0.250000 |
| 1 | 0.257549 | 0.209259 | 0.368421 | ... | 0.261682 | 0.228571 | 0.169355 |
| 2 | 0.238011 | 0.262963 | 0.210526 | ... | 0.224299 | 0.200000 | 0.266129 |
| 3 | 0.282416 | 0.253704 | 0.276316 | ... | 0.214953 | 0.291429 | 0.225806 |
| 4 | 0.218472 | 0.237037 | 0.236842 | ... | 0.214953 | 0.211429 | 0.209677 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 3995 | 0.289520 | 0.227778 | 0.421053 | ... | 0.224299 | 0.234286 | 0.241935 |
| 3996 | 0.253996 | 0.229630 | 0.381579 | ... | 0.233645 | 0.217143 | 0.225806 |
| 3997 | 0.236234 | 0.216667 | 0.250000 | ... | 0.252336 | 0.188571 | 0.241935 |
| 3998 | 0.275311 | 0.251852 | 0.236842 | ... | 0.196262 | 0.360000 | 0.266129 |
| 3999 | 0.291297 | 0.244444 | 0.263158 | ... | 0.271028 | 0.165714 | 0.250000 |
4000 rows × 656 columns
Each row represents synthetic batting statistics for the 2023 season, given each player's hypothesized batting ability in that "possible world." Eash player's at-bats is the same as in the actual 2023 season.
From these synthetic replays of 2023, we can estimate plausible means and standard deviations of observed batting average.
Click to see code
# get the mean and standard devation on ability for each sample world
mean_synth_vec = synthetic_hitrate_frame.mean(axis=1)
std_synth_vec = synthetic_hitrate_frame.std(axis=1)
# get the average mean and standard deviation over all sample worlds.
mean_synth = mean_synth_vec.mean()
std_synth = std_synth_vec.mean()
print(f'Mean observed batting average: {mean_ba:.3f}, standard deviation {std_ba:.3f}.')
print(f'Mean synthetic batting average observations: {mean_synth:.3f}, standard deviation {std_synth:.3f}.')
Mean observed batting average: 0.227, standard deviation 0.075.
Mean synthetic batting average observations: 0.244, standard deviation 0.078.
This is much closer to what was actually observed! We can also plot the distribution of batting average standard deviations in each synthetic season, and compare them to the actual observed batting average standard deviaion.
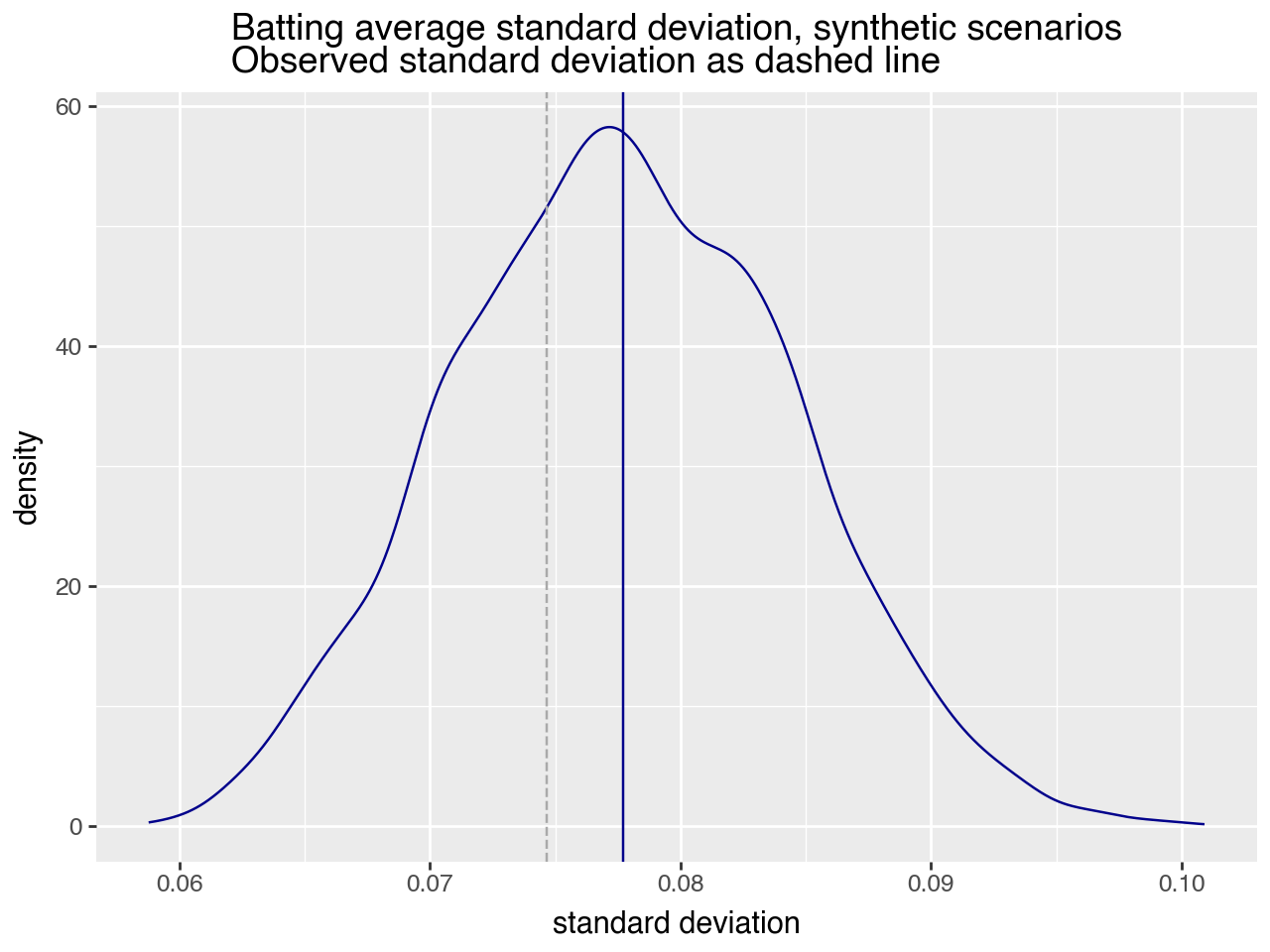
The distribution of batting-average standard deviations, with their mean, in dark blue. The gray dashed line is the actual batting-average standard deviation.
Once we simulate the at-bats, the behaviors in the synthetic worlds are consistent with what was observed in the actual data: observed batting averages vary more widely than innate batting abilities. This also gives us confidence that our model is a reasonable approximation of the real world baseball hit generation process. Specifically, it's an approximation we can use to answer the questions we want to ask, like "who are the best batters?".
Estimate What You Want to Know, Not Just What You Can Observe
As we've seen in the above example, an advantage of probabilistic modeling is that the analyst is able to distinguish between observations and (potentially unobservable) quantities of interest. If you, the analyst, can describe a probabilistic process that relates what you can see to what you actually need to know, then probabilistic modeling programs like Stan can estimate these quantities for you.
By specifying the process to describe your problem and your task goal, you can add in prior knowledge or assumptions about the domain in a principled, documentable way, without having to resort to ad-hoc tweaks or data processing.
In addition, probabilistic modeling systems that are based on Monte Carlo sampling (like Stan) provide samples of "possible worlds" that are consistent with the training data. You can use these samples not only to calculate point estimates of quantities of interest, but also uncertainty intervals around those estimates. You can also use the possible worlds to run simulations and scenarios (like, "who are the top 10 players in each possible world?") to further help you in decision-making.
Of course, the estimates can only be as good as the process that you describe. But as your understanding of and intuitions about these processes improve, then so, too, can your model.
By innate, I don't mean some kind of "natural-born" ability; a player's batting ability is no doubt honed by training and practice. I merely use the word innate to emphasize that the probability of a given player making a hit is not necessarily the same as the observed rate at which they made hits during a season.
↩︎Data from the Lahman Baseball Database, currently available from the Society for American Baseball Research (SABR). The Lahman R package provides an R interface to the database, as well.
↩︎See Evan Miller's article How Not To Sort By Average Rating for an alternative, frequentist solution to the "sort by rating" problem, in the context of product reviews.
↩︎All career batting averages as given by Wikipedia on May 19, 2026.
↩︎